Cuando comenzó la pandemia tuvimos largas conversaciones con mi mentor, J. Sunil Rao, acerca de la situación. Las conversaciones fueron interesantes y enriquecedoras por la diferencia de opiniones y porque solemos oírnos el uno al otro con mucho respeto. El caso es que decidimos hacer algo en vez de quedarnos solo discutiendo.
Hay un tema que me ha interesado por años y es el de los sesgos en las publicaciones científicas. De hecho, una de mis publicaciones favoritas es la de John Ioannidis llamada ¿Por qué la mayoría de resultados de investigación publicados son falsos?1 Es uno de los artículos científicos más citados de la historia y va en contra de la mayoría de los otros artículos científicos, así que el contraste es, por decir lo menos, interesante.
Uniendo estos dos asuntos, COVID-19 y sesgo en publicaciones académicas, a Sunil se le ocurrió que podríamos utilizar un resultado reciente de Isaiah Andrews y Maximilian Kasy sobre cómo corregir el sesgo en las publicaciones científicas para corregir también el sesgo en la detección de COVID-19.2 El resultado fue un artículo bastante esclarecedor publicado en el Journal of Theoretical Biology, con una corrección al sesgo en el muestreo de COVID-19 que resultó siendo muy fácil de implementar.3 El resumen del artículo, traducido al español, dice lo siguiente:
Las pruebas de COVID-19 se han convertido en la forma habitual de estimar la prevalencia, cosa que luego pasa a influir en la toma de decisiones en salud pública para contener y mitigar la propagación de la enfermedad. Los diseños muestrales usados suelen estar sesgados porque no reflejan la realidad de la población. Por ejemplo, es más probable que individuos con síntomas fuertes reciban la prueba en comparación con individuos con individuos que no presenten síntomas. Esta situación resulta en estimaciones sesgadas de prevalencia (demasiado altas). Las correcciones posteriores al muestreo no siempre son posibles. Presentamos aquí una metodología sencilla para la corrección del sesgo, derivada y adaptada de una corrección para sesgo en publicaciones en estudios de meta-análisis. La metodología es lo suficientemente general para permitir una amplia variedad de modificación que la haga más útil en la práctica. La implementación es fácilmente realizable utilizando tan solo la información ya recolectada. Por medio de un ejemplo y de dos bases de datos reales mostramos que las correcciones al sesgo pueden aportar reducciones dramáticas en el error de estimación.
La idea del artículo es sencilla: dada la emergencia, las pruebas de COVID-19 se han hecho principalmente a personas que al menos sospechan que pudieran haber tenido la enfermedad y estas pruebas se han tomado como una muestra a partir de la cual se está infiriendo la prevalencia. Por lo tanto, la prevalencia está altamente sobreestimada. Esto hace necesaria una corrección.
El modelo
Lo que sigue es intenso en notación matemática, aunque los conceptos son bastante sencillos. Como puede ser de provecho para cierta parte del análisis de la situación actual, voy a presentar los resultados más importantes aquí.
Considérese una población 
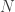

- el subconjunto de individuos asintomáticos no infectados,
- el subconjunto de individuos asintomáticos infectados,
- el subconjunto de individuos sintomáticos no infectados y
- el subconjunto de individuos sintomáticos infectados.
Llamaremos 


Definimos también una variable aleatoria 




Así las cosas, el subíndice 





Bajo esta notación, la proporción de individuos con sintomatología 

Y la proporción de prevalencia, está dada por

luego la proporción de no infectados es 

Ahora introducimos una variable aleatoria 




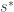
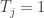


En resumen, para 
es la probabilidad de estar en la categoría
y tener una prueba de COVID-19.
es la probabilidad de que un individuo infectado en la categoría
es la probabilidad condicional de estar infectado dado
es la proporción real de personas con sintomatología
Además, tenemos los siguientes órdenes:




La intuición detrás de tales órdenes es que los individuos sintomáticos tienen mayor probabilidad de recibir la prueba que los asintomáticos (2), mayor probabilidad de hacer la prueba a individuos contagiados que los asintomáticos (3), mayor probabilidad condicional de estar infectados dentro de su grupo de sintomáticos que los asintomáticos (4) y son un grupo más pequeño que el de los asintomáticos (5).
Note que en (*) solo dimos la distribución categórica poblacional 
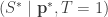

![f_{S | \mathbf p}(s | \vec p) = f_{S^*| \mathbf p^*, T}\left(s | \vec p, 1\right) = \frac{P\left[ T=1 | S^* = s, \mathbf p^* = \vec p \right]}{P\left[ T=1 | \mathbf p^* = \vec p \right]} f_{S^*|\mathbf p^*}\left( s |\vec p \right)](https://s0.wp.com/latex.php?latex=f_%7BS+%7C+%5Cmathbf+p%7D%28s+%7C+%5Cvec+p%29+%3D+f_%7BS%5E%2A%7C+%5Cmathbf+p%5E%2A%2C+T%7D%5Cleft%28s+%7C+%5Cvec+p%2C+1%5Cright%29%C2%A0%3D%C2%A0+%5Cfrac%7BP%5Cleft%5B+T%3D1+%7C+S%5E%2A+%3D+s%2C+%5Cmathbf+p%5E%2A+%3D+%5Cvec+p+%5Cright%5D%7D%7BP%5Cleft%5B+T%3D1+%7C+%5Cmathbf+p%5E%2A+%3D+%5Cvec+p+%5Cright%5D%7D+f_%7BS%5E%2A%7C%5Cmathbf+p%5E%2A%7D%5Cleft%28+s+%7C%5Cvec+p+%5Cright%29&bg=ffffff&fg=323232&s=0&c=20201002)
donde la primera igualdad no es más que convención de notación y la segunda se obtiene a partir del teorema de Bayes. Observe que el numerador del cociente en la última igualdad, ![P\left[ T=1 | S^* = s, \mathbf p^* = \vec p \right]](https://s0.wp.com/latex.php?latex=P%5Cleft%5B+T%3D1+%7C+S%5E%2A+%3D+s%2C+%5Cmathbf+p%5E%2A+%3D+%5Cvec+p+%5Cright%5D&bg=ffffff&fg=323232&s=0&c=20201002)

![E[p(S^*) | \textbf p^* = \vec p]](https://s0.wp.com/latex.php?latex=E%5Bp%28S%5E%2A%29+%7C+%5Ctextbf+p%5E%2A+%3D+%5Cvec+p%5D&bg=ffffff&fg=323232&s=0&c=20201002)
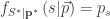
![f_{S | \mathbf p}(s | \vec p) = \frac{p (s)}{E[p(S^*) | \textbf p^* = \vec p]} p_s. \ \ \ \ \ \ \ \ \ \ \ \ \ \text{(6)}](https://s0.wp.com/latex.php?latex=f_%7BS+%7C+%5Cmathbf+p%7D%28s+%7C+%5Cvec+p%29+%3D+%5Cfrac%7Bp+%28s%29%7D%7BE%5Bp%28S%5E%2A%29+%7C+%5Ctextbf+p%5E%2A+%3D+%5Cvec+p%5D%7D+p_s.+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5Ctext%7B%286%29%7D&bg=ffffff&fg=323232&s=0&c=20201002)
Suponiendo que no hay error en las pruebas (ausencia de falsos positivos y negativos), sabemos la cantidad exacta de personas infectadas en la muestra. Incluso, bajo un procedimiento similar al anterior, podemos saber a qué categoría pertenecen. Por lo tanto, para 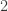
![f_{S| \textbf p} \left( s^{(1)}| \vec p \right) = \frac{p \left(s^{(1)} \right)}{E[p(S^*) | \textbf p^* = \vec p]} p_s^{(1)}. \ \ \ \ \ \ \ \ \ \ \ \ \text{(7)}](https://s0.wp.com/latex.php?latex=f_%7BS%7C+%5Ctextbf+p%7D+%5Cleft%28+s%5E%7B%281%29%7D%7C+%5Cvec+p+%5Cright%29%C2%A0%3D+%C2%A0%5Cfrac%7Bp+%5Cleft%28s%5E%7B%281%29%7D+%5Cright%29%7D%7BE%5Bp%28S%5E%2A%29+%7C+%5Ctextbf+p%5E%2A+%3D+%5Cvec+p%5D%7D+p_s%5E%7B%281%29%7D.+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5Ctext%7B%287%29%7D&bg=ffffff&fg=323232&s=0&c=20201002)
Si (6) y (7) fueran estimadores insesgados, serían respectivamente 

![\frac{p (1)}{E[p(S^*) | \textbf p^* = \vec p]} p_1 + \frac{p (2)}{E[p(S^*) | \textbf p^* = \vec p]} p_2, \ \ \ \ \ \ \ \ \ \ \text{(8)}](https://s0.wp.com/latex.php?latex=%C2%A0%5Cfrac%7Bp+%281%29%7D%7BE%5Bp%28S%5E%2A%29+%7C+%5Ctextbf+p%5E%2A+%3D+%5Cvec+p%5D%7D+p_1+%2B+%C2%A0%5Cfrac%7Bp+%282%29%7D%7BE%5Bp%28S%5E%2A%29+%7C+%5Ctextbf+p%5E%2A+%3D+%5Cvec+p%5D%7D+p_2%2C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5Ctext%7B%288%29%7D&bg=ffffff&fg=323232&s=0&c=20201002)
y el estimador total sesgado de prevalencia es
![\frac{p \left(1^{(1)} \right)}{E[p(S^*) | \textbf p^* = \vec p]} p_1^{(1)} + \frac{p \left(2^{(1)} \right)}{E[p(S^*) | \textbf p^* = \vec p]} p_2^{(1)}. \ \ \ \ \ \ \ \ \text{(9)}](https://s0.wp.com/latex.php?latex=%5Cfrac%7Bp+%5Cleft%281%5E%7B%281%29%7D+%5Cright%29%7D%7BE%5Bp%28S%5E%2A%29+%7C+%5Ctextbf+p%5E%2A+%3D+%5Cvec+p%5D%7D+p_1%5E%7B%281%29%7D+%2B+%5Cfrac%7Bp+%5Cleft%282%5E%7B%281%29%7D+%5Cright%29%7D%7BE%5Bp%28S%5E%2A%29+%7C+%5Ctextbf+p%5E%2A+%3D+%5Cvec+p%5D%7D+p_2%5E%7B%281%29%7D.+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5Ctext%7B%289%29%7D&bg=ffffff&fg=323232&s=0&c=20201002)
Corrección del sesgo
Definidas las cosas de esta manera, corregir el sesgo en las ecuaciones (6) y (7) se vuelve bastante sencillo: lo único que debe hacerse es multiplicar el lado derecho de cada una de estas ecuaciones por el inverso del cociente que aparece en ellas. Específicamente, la corrección del sesgo estaría dada por 
![C(x) = \frac{P\left[ T=1 | \textbf p^* = \vec p \right]}{p(x)} \ \ \ \ \ \ \ \ \ \ \ \text{(10)}](https://s0.wp.com/latex.php?latex=C%28x%29+%3D+%5Cfrac%7BP%5Cleft%5B+T%3D1+%7C+%5Ctextbf+p%5E%2A+%3D+%5Cvec+p+%5Cright%5D%7D%7Bp%28x%29%7D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5C+%5Ctext%7B%2810%29%7D&bg=ffffff&fg=323232&s=0&c=20201002)
Así, si por ejemplo remplazamos 

![\frac{P\left[ T=1 \mid \mathbf p^* = \vec p \right]}{p\left(1^{(1)}\right)} f_{S \mid \mathbf p}\left(1^{(1)} \mid \vec p \right) + \frac{P\left[ T=1 \mid \mathbf p^* = \vec p \right]}{p\left(2^{(1)}\right)}f_{S \mid \mathbf p}\left(2^{(1)} | \vec p\right)](https://s0.wp.com/latex.php?latex=%5Cfrac%7BP%5Cleft%5B+T%3D1+%5Cmid+%5Cmathbf+p%5E%2A+%3D+%5Cvec+p+%5Cright%5D%7D%7Bp%5Cleft%281%5E%7B%281%29%7D%5Cright%29%7D+f_%7BS+%5Cmid+%5Cmathbf+p%7D%5Cleft%281%5E%7B%281%29%7D+%5Cmid+%5Cvec+p+%5Cright%29+%2B+%5Cfrac%7BP%5Cleft%5B+T%3D1+%5Cmid+%5Cmathbf+p%5E%2A+%3D+%5Cvec+p+%5Cright%5D%7D%7Bp%5Cleft%282%5E%7B%281%29%7D%5Cright%29%7Df_%7BS+%5Cmid+%5Cmathbf+p%7D%5Cleft%282%5E%7B%281%29%7D+%7C+%5Cvec+p%5Cright%29&bg=ffffff&fg=323232&s=0&c=20201002)
El numerador a la derecha de la ecuación (10) puede estimarse fácilmente como 

Como ya aprendimos que la proporción de individuos muestreados es 
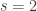

Trivialmente se obtiene entonces que la proporción corregida de asintomáticos es 
¿Qué significa lo anterior para nuestro análisis? Que en ausencia de mejor conocimiento, lo mejor que podemos hacer es generar un número aleatorio 

En cualquiera de los dos casos anteriores, la estimación de prevalencia entre asintomáticos estará dada por 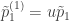
En resumen, para nuestro caso con solo las dos categorías de asintomáticos,
- Sintomáticos:
.
- Asintomáticos:
- Sintomáticos con el virus:
- Asintomáticos con el virus:
Ejemplo
El ejemplo a continuación ilustrará cómo funciona en la práctica el modelo bajo cuatro diferentes protocolos de muestreo. El ejemplo proviene de un artículo de Poletti et al con datos reales tomados de Lombardía, Italia, que fue uno de los grandes focos de la enfermedad en la primera oleada.7
En una muestra de 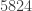


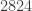

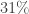
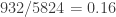

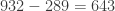
Protocolo de muestreo 1. La muestra está compuesta por 
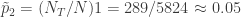
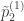
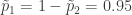
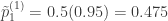

Protocolo de muestro 2. La muestra está compuesta por 
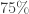
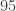




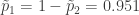

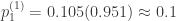
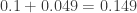

Protocolo de muestreo 3. En este escenario tenemos 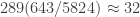





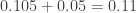
Protocolo de muestro 4. Esta es una muestra verdaderamente aleatoria, es decir, como debería ser una muestra ideal. Digamos que 


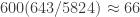
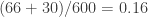




Notas
- Ioannidis J. Why Most Published Research Findings Are False. PLoS Med. 2005 Aug; 2(8): e124. ↩
- Andrews, I., Kasy, M., 2019. Identification of and correction for publication bias. Am. Econ. Rev. 109 (8), 2766–2794. ↩
- Díaz-Pachón D.A., Rao J.S. A simple correction for COVID-19 sampling bias. J. Theor. Biol. 512 (2021) 110556. Una versión pre-publicada del artículo puede encontrarse aquí. ↩
- En el artículo consideramos que podría haber más de dos síntomas o grados de síntomas (
, para
), pero aquí, para simplificar la explicación, solo consideraremos las dos posibilidades mencionadas: presencia o ausencia de ellos. ↩
- Dembski, W.A., Marks, R.J., II, 2009. Bernoulli’s principle of insufficient reason and conservation of information in computer search. In: Proc. of the 2009 IEEE International Conference on Systems, Man, and Cybernetics. San Antonio, TX. pp. 2647–2652. ↩
- Jaynes, E.T., 1957. Information theory and statistical mechanics. Phys. Rev. 106 (4), 620–630. Véase también Díaz-Pachón, D.A., Marks II., R.J., 2020. Generalized Active Information: Extensions to Unbounded Domains. BIO-Complexity 2020 (3), 1–6. ↩
- Poletti, P., Tirani, M., Cereda, D., Trentini, F., Guzzetta, G., Sabatino, G., Marziano, V., Castrofino, A., Grosso, F., del Castillo, G., Piccarreta, R., ATS Lombardy COVID-19 Task Force, A. Andreassi, A. Melegaro, M. Gramegna, M. Ajelli, and S. Merler., 2020. Probability of symptoms and critical disease after SARS-CoV-2 infection. Pre-impresión.↩
 , se dice que la variable está indexada en el tiempo, y se define un camino aleatorio como la función
, se dice que la variable está indexada en el tiempo, y se define un camino aleatorio como la función  . Es decir, para cada elemento
. Es decir, para cada elemento  , vemos cómo se comporta el proceso a medida que el tiempo va avanzando. Toda propiedad que adjudiquemos al proceso estocástico
, vemos cómo se comporta el proceso a medida que el tiempo va avanzando. Toda propiedad que adjudiquemos al proceso estocástico 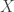 , en realidad es una propiedad en un conjunto
, en realidad es una propiedad en un conjunto  tal que
tal que 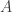 tiene probabilidad 1.
tiene probabilidad 1.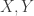 se dicen equivalentes si
se dicen equivalentes si ![\textbf P[X\neq Y]=0](https://s0.wp.com/latex.php?latex=%5Ctextbf+P%5BX%5Cneq+Y%5D%3D0&bg=ffffff&fg=323232&s=0&c=20201002) , donde el evento
, donde el evento  está definido como
está definido como .
. si
si![\forall t\in\mathbb R^+,\ \ \textbf P[\omega\in\Omega:X_t(\omega)\neq Y_t(\omega)]=0](https://s0.wp.com/latex.php?latex=%5Cforall+t%5Cin%5Cmathbb+R%5E%2B%2C%5C+%5C+%5Ctextbf+P%5B%5Comega%5Cin%5COmega%3AX_t%28%5Comega%29%5Cneq+Y_t%28%5Comega%29%5D%3D0&bg=ffffff&fg=323232&s=0&c=20201002) ,
,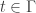 , se tiene que
, se tiene que  y
y  son variables aleatorias equivalentes.
son variables aleatorias equivalentes. son indistinguibles si
son indistinguibles si![\textbf P[\omega\in\Omega:\forall t\in\mathbb R^+, X_t(\omega)\neq Y_t(\omega)]=0](https://s0.wp.com/latex.php?latex=%5Ctextbf+P%5B%5Comega%5Cin%5COmega%3A%5Cforall+t%5Cin%5Cmathbb+R%5E%2B%2C+X_t%28%5Comega%29%5Cneq+Y_t%28%5Comega%29%5D%3D0&bg=ffffff&fg=323232&s=0&c=20201002) ,
, , el conjunto de los racionales. Para cada
, el conjunto de los racionales. Para cada  , tenemos que
, tenemos que![\textbf P[\omega\in\Omega:X_q(\omega)\neq Y_q(\omega)]=0](https://s0.wp.com/latex.php?latex=%5Ctextbf+P%5B%5Comega%5Cin%5COmega%3AX_q%28%5Comega%29%5Cneq+Y_q%28%5Comega%29%5D%3D0&bg=ffffff&fg=323232&s=0&c=20201002) .
.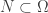 como
como ,
,![\textbf P[N]=0](https://s0.wp.com/latex.php?latex=%5Ctextbf+P%5BN%5D%3D0&bg=ffffff&fg=323232&s=0&c=20201002) . Considérense los caminos aleatorios de
. Considérense los caminos aleatorios de  en
en 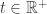 , existe una sucesión de racionales
, existe una sucesión de racionales  que decrece a
que decrece a  . De modo que, por la continuidad por derecha,
. De modo que, por la continuidad por derecha,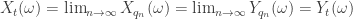 .
.![\Omega=[0,1]](https://s0.wp.com/latex.php?latex=%5COmega%3D%5B0%2C1%5D&bg=ffffff&fg=323232&s=0&c=20201002) ,
, 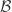 los conjuntos de Borel de
los conjuntos de Borel de 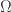 y
y  la medida de Lebesgue en dicho espacio muestral. Definimos el proceso
la medida de Lebesgue en dicho espacio muestral. Definimos el proceso  de la siguiente manera:
de la siguiente manera: si
si  ,
, en otro caso,
en otro caso, es la parte entera de
es la parte entera de 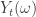 tiene discontinuidades contables. Sin embargo, para
tiene discontinuidades contables. Sin embargo, para  .
.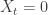 , para todo
, para todo ![\textbf P[\omega\in\Omega:X_t(\omega)=Y_t(\omega)]=1](https://s0.wp.com/latex.php?latex=%5Ctextbf+P%5B%5Comega%5Cin%5COmega%3AX_t%28%5Comega%29%3DY_t%28%5Comega%29%5D%3D1&bg=ffffff&fg=323232&s=0&c=20201002) , pero la probabilidad del conjunto en el que los caminos coinciden es cero.
, pero la probabilidad del conjunto en el que los caminos coinciden es cero. ; es decir,
; es decir,  Sin embargo, esta definición carece de ciertos atributos importantes y se requiere una formulación más precisa.
Sin embargo, esta definición carece de ciertos atributos importantes y se requiere una formulación más precisa.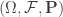 . Un elemento aleatorio en un espacio medible
. Un elemento aleatorio en un espacio medible 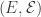 es una función medible
es una función medible  que va del espacio de probabilidad al espacio medible:
que va del espacio de probabilidad al espacio medible: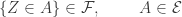 ,
,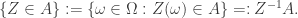
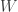 es simplemente un caso particular de un elemento aleatorio en el que el conjunto de llegada son los reales
es simplemente un caso particular de un elemento aleatorio en el que el conjunto de llegada son los reales 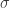 -álgebra de Borel
-álgebra de Borel  .
. , indexadas en el conjunto
, indexadas en el conjunto  , donde cada
, donde cada  .
.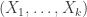 también es un proceso estocástico en el cual
también es un proceso estocástico en el cual  .
. , entonces
, entonces 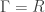 , entonces
, entonces  , entonces
, entonces  y
y  son variables aleatorias independientes y uniformemente distribuidas en la bola
son variables aleatorias independientes y uniformemente distribuidas en la bola 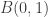 en
en  dimensiones. Entonces
dimensiones. Entonces![\lim_{d\rightarrow\infty}\textbf P[|\textbf X(d)|>3/4]=1](https://s0.wp.com/latex.php?latex=%5Clim_%7Bd%5Crightarrow%5Cinfty%7D%5Ctextbf+P%5B%7C%5Ctextbf+X%28d%29%7C%3E3%2F4%5D%3D1&bg=ffffff&fg=323232&s=0&c=20201002)
![\lim_{d\rightarrow\infty}(\sup {\textbf P[|\textbf X(d)-x|\leq1]:x\in\mathbb R^d,|x|\geq 3/4})=0](https://s0.wp.com/latex.php?latex=%5Clim_%7Bd%5Crightarrow%5Cinfty%7D%28%5Csup+%7B%5Ctextbf+P%5B%7C%5Ctextbf+X%28d%29-x%7C%5Cleq1%5D%3Ax%5Cin%5Cmathbb+R%5Ed%2C%7Cx%7C%5Cgeq+3%2F4%7D%29%3D0&bg=ffffff&fg=323232&s=0&c=20201002)
![\lim_{d\rightarrow\infty}\textbf P[|\textbf X(d)-\textbf Y(d)|\leq1]=0](https://s0.wp.com/latex.php?latex=%5Clim_%7Bd%5Crightarrow%5Cinfty%7D%5Ctextbf+P%5B%7C%5Ctextbf+X%28d%29-%5Ctextbf+Y%28d%29%7C%5Cleq1%5D%3D0&bg=ffffff&fg=323232&s=0&c=20201002) .
.![\textbf P[|\textbf X(d)|>3/4]=1-\textbf P[|\textbf X(d)|\leq3/4]](https://s0.wp.com/latex.php?latex=%5Ctextbf+P%5B%7C%5Ctextbf+X%28d%29%7C%3E3%2F4%5D%3D1-%5Ctextbf+P%5B%7C%5Ctextbf+X%28d%29%7C%5Cleq3%2F4%5D&bg=ffffff&fg=323232&s=0&c=20201002)

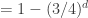
 . Aquí
. Aquí 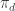 es el volumen de la bola de radio
es el volumen de la bola de radio  .
. converge a
converge a  . Escríbase
. Escríbase  y
y  . Por simetría (la bola unitaria es igual en todas las direcciones), puede suponerse que
. Por simetría (la bola unitaria es igual en todas las direcciones), puede suponerse que 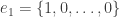 , luego
, luego  tiene la misma distribución que
tiene la misma distribución que  y por lo tanto también la misma distribución que
y por lo tanto también la misma distribución que  . De nuevo, por simetría, las componentes de
. De nuevo, por simetría, las componentes de ![\textbf E[|X^1(d)|^2]\leq 1/d](https://s0.wp.com/latex.php?latex=%5Ctextbf+E%5B%7CX%5E1%28d%29%7C%5E2%5D%5Cleq+1%2Fd&bg=ffffff&fg=323232&s=0&c=20201002) , de modo que
, de modo que  converge a
converge a  y, por lo tanto, también en probabilidad.
y, por lo tanto, también en probabilidad. mientras tenga HTML en el cliente del correo.
mientras tenga HTML en el cliente del correo. y
y  . El referee dice que las dos funciones son del mismo orden cuando
. El referee dice que las dos funciones son del mismo orden cuando  , cosa que es fácilmente verificable, como procederé a mostrar. Decir que las dos funciones son del mismo orden cerca de 1 es decir
, cosa que es fácilmente verificable, como procederé a mostrar. Decir que las dos funciones son del mismo orden cerca de 1 es decir  , donde
, donde  es una constante diferente de
es una constante diferente de 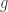 crece más rápido que
crece más rápido que 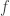 y si
y si  .
. .
.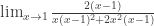 .
.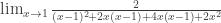 .
. . La pregunta que me surge —la que inspira esta entrada— es cómo el señor referee encontró
. La pregunta que me surge —la que inspira esta entrada— es cómo el señor referee encontró 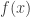 (sobre todo porque la encontró de tal manera que perjudica lo que quiero hacer con
(sobre todo porque la encontró de tal manera que perjudica lo que quiero hacer con  ). Una vez tengo
). Una vez tengo 
Debe estar conectado para enviar un comentario.